CPU 사용률은 낮은데 왜 쓰로틀링이 발생할까
CPU 사용률은 한 자릿수였는데 OOMKilled가 반복됐다. 메모리를 늘려도 죽었다. 근본 원인은 CPU 쓰로틀링이었다. CPU가 부족하면 GC가 지연되고, GC 지연은 메모리 고갈로 이어진다. 그런데 어떻게 사용률이 낮은데 쓰로틀링이 발생하는 걸까. K8s CPU limits가 커널 레벨에서 어떻게 구현되는지 따라가면 답이 보인다.
메모리 문제로 보였지만 CPU가 원인이었다
운영 중인 Tempo Ingester에서 OOMKilled가 반복됐다. 메모리 사용량은 급증하는데 CPU 사용률 지표는 안정적인 저부하 상태를 유지했다.


메모리가 부족하다고 판단해 Pod 메모리를 증설했지만 OOMKilled는 계속됐다. 그때 CPU 쓰로틀링 지표를 확인했다.

CPU 쓰로틀링이 발생하는 구간에서 메모리가 급증했다. 인과관계가 보였다. CPU가 throttled되면 JVM GC 같은 메모리 회수 작업이 지연되고, 회수되지 못한 메모리가 쌓여 OOM으로 이어진다. 그런데 CPU 사용률은 분명히 낮았다. 대시보드에서 CPU가 여유로운 것처럼 보이는데 왜 쓰로틀링이 발생하는가가 탐구의 출발점이었다.
requests는 소프트 리밋, limits는 하드 리밋이다
K8s가 CPU를 관리하는 두 값부터 구분해야 한다.
requests는 스케줄링의 기준이다. 스케줄러는 노드의 가용 리소스와 Pod의 requests를 비교해 배치 위치를 결정하고, CPU 경합이 발생하면 requests 값에 비례해 CPU 시간을 분배한다. 핵심은 경합이 없으면 requests보다 더 많은 CPU를 자유롭게 쓸 수 있다는 것이다. 소프트 리밋이다.

limits는 다르다. 컨테이너가 사용할 수 있는 절대적 상한선으로, 노드에 유휴 CPU가 아무리 많아도 limits를 초과하는 순간 커널이 해당 컨테이너의 CPU 사용을 강제로 멈춘다. 이게 CPU 쓰로틀링이다. 경합과 무관하게 동작하는 하드 리밋이다.

이 구분이 중요한 이유가 있다. requests는 “다른 파드가 내 CPU를 빼앗지 못하도록” 보호하고, limits는 “내가 쓸 수 있는 CPU 총량을 강제로 자른다”. Noisy Neighbor 방어는 requests가 담당하지, limits가 아니다.
limits는 100ms 주기로 CPU를 배급한다
K8s의 requests와 limits는 리눅스 커널의 cgroups와 CFS(Completely Fair Scheduler) 를 통해 구현된다.
requests→cpu.weight: CFS 스케줄러가 경합 시 이 가중치에 비례해 CPU 시간을 분배한다limits→cpu.max: CFS 대역폭 제어(Bandwidth Control) 메커니즘으로 동작한다
CFS 대역폭 제어가 쓰로틀링의 실체다. CFS는 CPU 시간을 100ms 주기(cpu.cfs_period_us) 로 나누고, 각 주기마다 cgroup이 사용할 수 있는 최대 시간(cpu.cfs_quota_us)을 할당한다. limits: 200m으로 설정하면 컨테이너는 매 100ms 주기마다 20ms의 CPU 시간만 사용할 수 있다. 20ms를 모두 소진하면 다음 주기가 시작될 때까지 남은 80ms 동안 실행이 강제 중지된다.
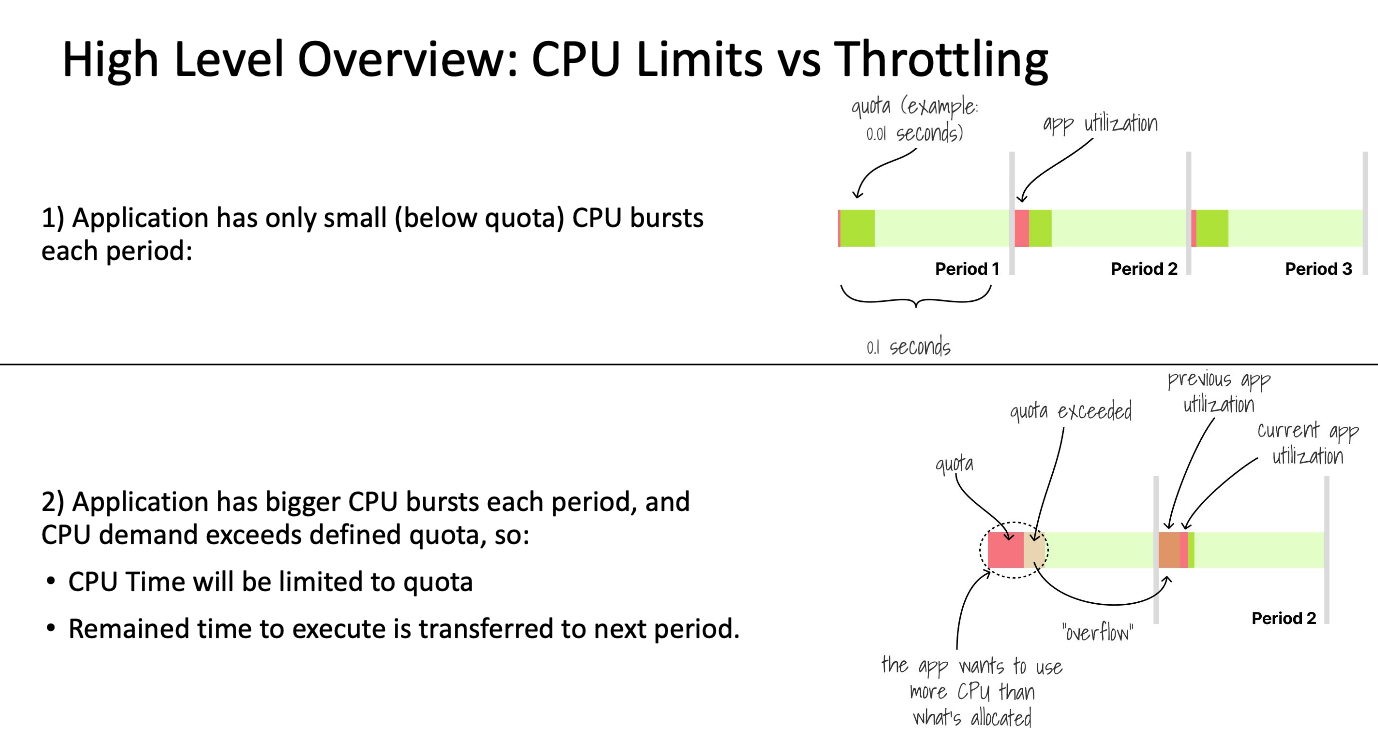
여기서 핵심이 드러난다. 쓰로틀링은 100ms 단위의 미시적 현상이다. 매 100ms 주기마다 “20ms 사용 → 80ms 강제 정지”가 반복될 수 있다.
5분 평균 사용률은 100ms 쓰로틀링을 숨긴다
Grafana에서 자주 쓰는 CPU 지표 두 가지를 비교하면 해상도 차이가 보인다.
CPU Usage (사용률):
sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_rate5m{...})
rate(...[5m])은 누적 CPU 시간의 5분간 평균 변화율이다. 평균이다.
CPU Throttling (쓰로틀링 비율):
sum(increase(container_cpu_cfs_throttled_periods_total{...}[$__rate_interval]))
/ sum(increase(container_cpu_cfs_periods_total{...}[$__rate_interval]))
전체 CFS 스케줄링 주기 중 쓰로틀링이 발생한 주기의 비율이다. 100ms 단위로 집계된다.
Tempo Ingester의 워크로드 특성이 여기서 문제가 됐다. Ingester는 block completing 요청이 들어올 때 vParquet 변환 작업으로 CPU를 집중적으로 사용(Burst)하고, 나머지 시간은 유휴 상태다. limits: 200m 컨테이너가 100ms 주기 중 처음 20ms 동안 CPU를 100% 사용하면, 할당량을 소진해 나머지 80ms 동안 쓰로틀링된다. 쓰로틀링 지표는 급증하지만, 5분 평균 CPU 사용률은 이 짧은 버스트를 긴 유휴 시간과 함께 평균 내어 5% 정도의 낮은 값으로 표시한다.
대시보드는 CPU가 여유로워 보이지만, 실제로는 애플리케이션이 CPU를 필요로 하는 매 순간마다 limits에 부딪히고 있었다.
| 지표 | 시간 해상도 | 버스트 감지 |
|---|---|---|
| CPU Usage (rate 5m) | 5분 평균 | 숨김 |
| CPU Throttling | 100ms 주기 | 감지 |
CPU 사용률만 보고 “CPU가 충분하다”고 판단하면 안 된다. 쓰로틀링 비율을 반드시 함께 봐야 한다. 쓰로틀링 비율이 25%를 넘으면 심각한 쓰로틀링으로 판단한다.
CPU limits를 제거하면 Noisy Neighbor 문제가 생기지 않는가
많은 사람들이 limits를 Noisy Neighbor 방어를 위해 필요하다고 생각한다. 하지만 그 역할은 이미 requests가 수행한다.
requests는 최소한을 보장한다. K8s는 어떤 경우에도 각 컨테이너가 requests로 요청한 CPU를 보장하며, 다른 컨테이너가 아무리 많은 CPU를 사용해도 requests로 보장된 자원은 침범할 수 없다. CPU 경합이 발생할 때 requests 비율에 따라 공정하게 분배되므로, limits 없이도 특정 컨테이너가 CPU를 독점하지 못한다.
반면 limits는 노드에 유휴 CPU가 충분히 남아 있어도 컨테이너가 이를 사용하지 못하게 막는다. 갑작스러운 트래픽 증가나 CPU 집약적 작업이 필요할 때 성능을 낼 수 없고, 지연 시간 증가 → 타임아웃 → 백로그 누적 → 메모리 증가 → OOMKilled라는 간접적 연쇄로 이어진다.
결국 Noisy Neighbor를 막는 것은 requests이고, limits는 유휴 CPU를 못 쓰게 막는 제약일 뿐이다. 대부분의 경우 CPU limits를 제거하고 requests를 정확하게 설정하는 것이 유리하다.
이 탐구가 남긴 것
CPU limits는 CFS 대역폭 제어로 구현되며, 100ms 주기마다 할당된 CPU 시간을 초과하면 강제 중지된다. 노드의 유휴 CPU 여부와 무관하게 동작하는 하드 리밋이다.
CPU Usage 지표(5분 평균)는 버스트 패턴을 숨긴다. 짧은 순간에 집중적으로 CPU를 쓰고 나머지 시간은 유휴인 워크로드는 평균 사용률이 낮게 나오지만 매 100ms 주기마다 쓰로틀링이 발생할 수 있다. 쓰로틀링 비율 지표를 반드시 함께 봐야 한다.
CPU 쓰로틀링은 메모리 문제로 위장한다. CPU가 부족하면 GC 같은 백그라운드 작업이 지연되고, 지연된 GC는 메모리 고갈로 이어진다. OOMKilled가 발생했을 때 메모리만 늘리기 전에 CPU 쓰로틀링 지표를 먼저 확인해야 한다.
앞으로의 방향
CPU limits를 제거하기로 했다. 다음 단계는 requests를 정확하게 설정하는 것인데, 수동으로 잡으면 과소/과대 설정이 반복된다. VPA(Vertical Pod Autoscaler) 로 requests를 실제 사용 패턴에 맞게 자동 조정하는 구성을 검토 중이다.
쓰로틀링 알럿도 추가할 계획이다. CPU Usage 단독으로는 버스트 패턴을 감지하지 못하므로, container_cpu_cfs_throttled_periods_total / container_cpu_cfs_periods_total 비율이 25%를 초과할 때 알림을 발생시키는 룰을 Grafana에 추가할 예정이다.
남은 질문
CPU는 쓰로틀링으로 “느려지기만” 하고 프로세스가 죽지는 않는다. 그런데 메모리는 다르다. 메모리는 초과하면 프로세스가 즉시 죽는다. 이 차이가 requests와 limits 설정 전략에 어떤 영향을 줄까. CPU는 limits를 풀어야 한다면, 메모리도 같은 전략이 통할까.
→ 이 질문은 다음 글 K8s 메모리 request와 limit, 어떻게 설정해야 할까에서 탐구한다.
참고 자료
- Kubernetes Official Docs: Manage Resources Containers
- CPU Limits and Requests in Kubernetes
- Stop Using CPU Limits
정보 공백 요약
| # | 필요한 정보 | 이유 | 위치 |
|---|---|---|---|
| 1 | 메모리 급증 + OOMKilled 직전 구간 Grafana 스크린샷 | ”사용률 낮은데 OOM” 역설 상황의 시각적 증거 | 오프닝/배경 섹션 |